I Find Your Lack of Questions Disturbing
I feel a twinge of anxiety each time I submit a request to ChatGPT. Are my instructions clear? Could my words be misinterpreted? Does the model know anything about this topic?
Prompts were a low-stakes game with early models. The moment I clicked the “submit” button, I could tell if the AI was confused. All I had to do was click the “stop” button and try again. No harm, no foul.
It’s different with reasoning models like OpenAI’s GPT-o1. My stress builds as I watch that pulsating “Thinking…” message. Will I get the expected result, or will the model produce nonsense because it didn’t understand my prompt?
I don’t feel the same anxiety working with people. If something is unclear, people ask questions. I use OpenAI’s models daily, and I can’t remember the last time a model asked me a clarifying question.
You can test what I’m describing yourself. Open ChatGPT and type an ambiguous question like “How many people live in Springfield?” The model knows there are multiple towns named Springfield, but it often (not always) doesn’t bother to ask which one you’re talking about.

GPT-4o response
I forgave early models for their dearth of questions. They responded to queries in a single pass. The models didn’t have time to think. However, we’re months into AI’s “thinking slow” era. If anything, the problem seems to be getting worse.
I haven’t done a scientific study, but simple models seem more likely to generate questions than complex models. For example, I usually receive a clarifying question if I ask the old version of GPT-4 the population of Springfield. The same thing happens with Anthropic’s Claude Sonnet 3.5.
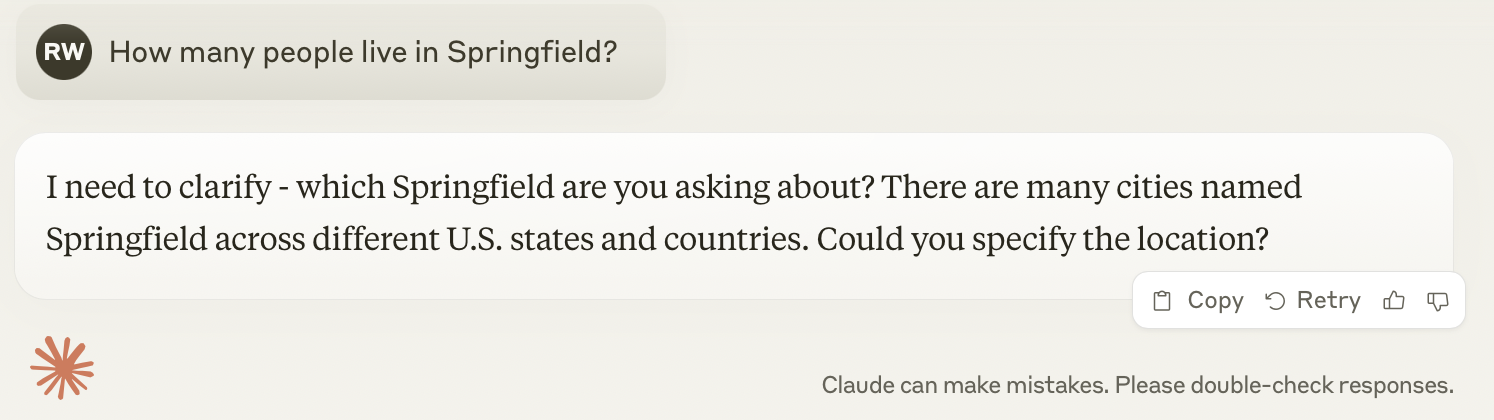
Sonnet 3.5 response
If I pose the question to the latest OpenAI model, GPT-1o, it usually tells me the population of every Springfield in the United States.
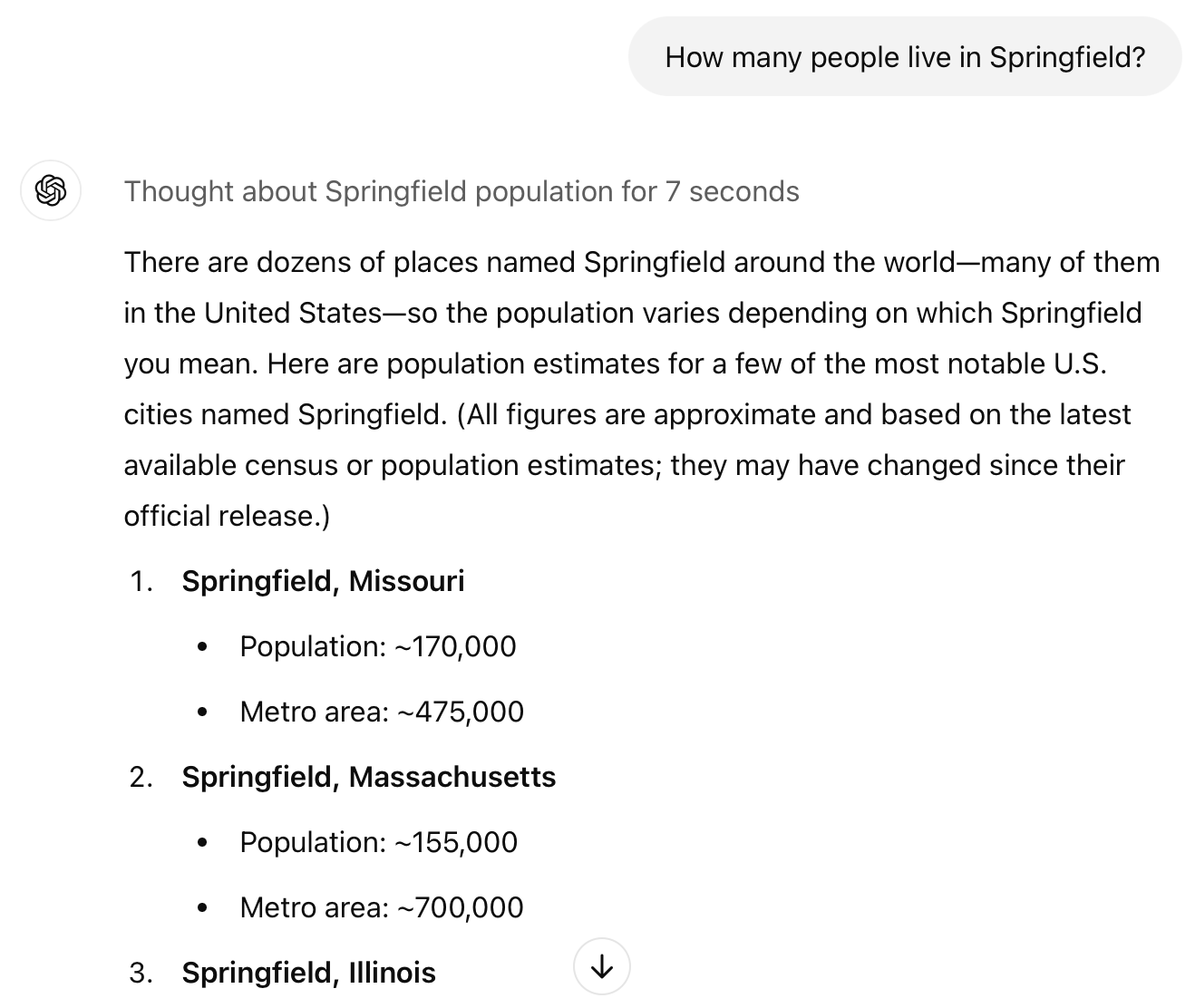
GPT-o1 response
The Springfield example is silly but emblematic of a deeper problem — AI models lack curiosity.
Brain in a Box
Picture yourself as an AI model trapped inside a data center. Your only connection to the outside world is a chat session with a random person. Your objective is to generate responses the human finds acceptable.
You have no idea who the human is on the other end of the line. Are they an adult or a child? What do they do for a living? Are they having a good day, or are they still annoyed about that driver who cut them off?
Imagine the questions that would be going through your head. That’s what I mean by curiosity. We ask questions to fill gaps in our understanding. We do it almost instinctively.
If you asked me for the population of Springfield, I’d give you a confused look and then ask whether you’re talking about Springfield, IL (close to where I live) or the fictional town of Springfield from The Simpsons.
My question serves two purposes. First, it solicits clarifying information from you. Second, it informs you about my thought process. Questions help us collaboratively and efficiently converge on optimal responses. They’re a critical building block for collective intelligence.
Questioning AGI
If you ask ChatGPT to write a bedtime story, it doesn’t regurgitate a story it found online. It generates a new story based on patterns encoded during the model’s training process. This concept is called generalization and is central to building artificial general intelligence (AGI).
A young child is less capable than an LLM by most measures. How many kindergartners can pass the bar exam? Yet, most experts would say young children possess artificial general intelligence, but LLMs don’t.
Why?
Children are curious. People who hang out with kids are familiar with their endless supply of random questions. How big is a blue whale? What does that sign mean? Where do babies come from?
Like AI models, children have an incomplete model of the world. Unlike AI, children ask questions to fill in the blanks.
AGI requires more than generalizing from patterns in training data. It also requires understanding where knowledge gaps exist and mechanisms for filling them. In short, AGI should be curious.
Almost There
The building blocks of artificial curiosity are in place. Ask ChatGPT to generate a list of questions about your favorite topic. AI models can ask thoughtful questions when prompted.
Models also know how to break complex problems into steps. Older models like GPT-3 rushed to generate responses. Newer models like GPT-o1 take their time crafting an approach before diving into the details.
What’s missing is a training process that rewards curiosity. AI training rewards responses that testers and users like. That objective function may produce questions on the margin but doesn’t instill curiosity.
One idea is to reward models for soliciting novel and relevant data during training. Provide a reward when humans prefer responses generated after the model asks questions. Don’t provide a reward when humans prefer responses generated before the questions.

Training AI Curiosity
Once models are in production, users could turn the “cost” of questions up and down like they can today for creativity (e.g., “temperature” setting on OpenAI models). I’d keep the curiosity dial turned down for simple or low-stakes queries to avoid excessive conversation. I’d crank it up for complex or high-stakes queries to prevent misunderstandings.
I’m surprised AI companies aren’t making more progress on curiosity, but that could be an unintended consequence of scaling laws. AI companies seem convinced that larger models and more training data are the path to AGI. Maybe they’re right, but they’ll probably get there faster with a bit of curiosity.
One day, an AI company will declare that it’s achieved AGI. When that time comes, I’ll have a simple test. Can the model figure out how to get the most out of me, or is it up to me to figure out how to get the most out of the model? Intelligent models are tools. Curious models are partners. I’m waiting for the latter.